
L’écriture algorithmique, couplée aux données sur lesquelles elle s’appuie, est capable de prévoir « probablement » nos comportements, de s’autocorriger en fonction de ses propres calculs que l’algorithme a rendus autonomes, ou de calculer les milliards de combinaisons possibles d’un jeu de stratégie comme les échecs ou le jeu de Go. Cependant, elle se distingue de l’intelligence humaine en cela qu’elle est incapable de créer quoi que soit, indépendamment d’une base de données et de calculs qui lui est assignée.
I.A., A.A., Informatique Avancée, Algorithmique Avancée, Algorithmique Apprenante, Apprentissage Automatique, ou Algorithmique Aléatoire. Hé bien oui, I.A., bien que – mal – traduit par Intelligence Artificielle, c’est tout cela l’I.A. Nul n’ayant eu l’outrecuidance de traduire Intelligence service par Service Intelligent, ni Computer Science par science du calculateur, il est difficilement compréhensible, hors une soumission veule à l’anglo-saxon et son soft power, d’avoir traduit Artificial Intelligence par Intelligence Artificielle.
Une langue porte une culture. Ainsi si le syntagme computer science fut traduit en 1957 en français par Informatique et computer par ordinateur, c’est dû aux racines latines de notre culture ; la science d’un instrument ou d’une pratique, ça n’a pas de sens en français, et plus généralement pour quelqu’un de culture latine. Les anglo-saxons sont des behavioristes (comportementalistes) pour l’essentiel. Les « tests de Turing » en témoignent. Il suffit qu’une machine se comporte sur un certain nombre de tests comme un humain pour que l’on décrète la machine intelligente, ce qui n’a aucun sens pour nous.
L’I.A, c’est tout d’abord de l’algorithmique bien conçue qui va de l’exploration combinatoire dirigée à l’apprentissage sous trois formes différentes associées pour ces dernières à de phénoménales puissances de calcul et de stockage de données (bases de données), en passant par des réseaux distribués dits réseaux de neurones.
Il s’agit fondamentalement de techniques informatiques qui s’appliquent dans des domaines algorithmiques pour lesquels, soit on ne sait pas les formuler, soit la complexité calculatoire est trop importante pour qu’on puisse espérer trouver un algorithme de résolution en temps raisonnable[1].
L’exploration combinatoire
Mon professeur[2] nous disait « qu’ il est interdit d’énumérer en univers combinatoire » ce à quoi j’ai répondu à l’époque : « il est interdit d’énumérer bêtement en univers combinatoire ».
Le problème vient d’une situation bien connue des algorithmiciens liée à l’énumération exhaustive des solutions d’un problème dont le nombre relève de la croissance exponentielle et que l’on nomme Complexité calculatoire. Sans entrer dans les détails, il existe des problèmes d’une complexité telle que, même avec un ordinateur un milliard de fois plus puissant que le plus puissant connu, le temps de vie de l’univers ne suffirait pas à le résoudre, c’est ce que l’on nomme le mur de la complexité.
Par exemple dans le jeu d’échecs, toutes les pièces ayant été disposées selon les règles, le nombre de parties possibles est de l’ordre de 10110 (1 suivi de 110 zéros !)[3] ce qui exclut toute possibilité d’énumération exhaustive des parties en vue de choisir quelle stratégie de jeu conduit à coup sûr à la victoire.
Depuis quelques années maintenant est apparue une autre technique plus générale qui est l’apprentissage algorithmique. Lorsque l’on sait spécifier exactement le résultat attendu, il peut être plus simple de programmer directement. Quand on veut faire effectuer une tâche par un ordinateur, on peut le programmer pour la traiter, ou pour apprendre à la traiter, ou par une combinaison des deux. Il est des situations où l’apprentissage est la seule solution raisonnablement possible.
La technologie d’apprentissage automatique ne se réduit pas aux jeux. Elle est déjà largement utilisée dans une multitude d’applications, reconnaissance faciale, aide au diagnostic, aide à la conduite automobile… C’est une méthode qui permet de découvrir, dans les données, des régularités ou trames dotées d’une utilité prédictive pour les événements futurs, mais sans pour autant fournir une théorie explicative. Par exemple, des sociétés comme Amazon ou Netflix font des recommandations d’achats pour leurs clients basées sur les prédictions d’algorithmes d’apprentissage à partir des achats antérieurs. Bien sûr, il n’y a pas de théorie disant le livre ou le film que vous allez aimer. Vos goûts peuvent même changer d’un instant à l’autre. Néanmoins, les algorithmes d’apprentissage automatique se sont révélés efficaces pour ce genre de recommandations et ce d’un point de vue statistique.
Rien de très intelligent de la part des machines
Rien de très intelligent de la part des machines, seulement (et c’est beaucoup) de la part de celles et ceux qui ont conçu les algorithmes dont on va essayer de donner ci-après une idée sans entrer dans des détails trop techniques.
D’un certain point de vue, l’apprentissage automatique, c’est du classement.
Il y a trois grands types d’apprentissage automatique en machine ; par renforcement ; supervisé ; et non supervisé. Les deux premiers sont un peu du même ordre.
Apprentissage par renforcement : une entité (un agent en informatique) est plus ou moins pénalisée ou renforcée en fonction de la nature de ses actions, et ce automatiquement à partir de critères inclus dans le programme de l’agent (je gagne, je perds).
Apprentissage non supervisé : là c’est un peu plus subtil, on laisse le programme trouver les points communs entre les exemples qu’on lui présente et on le dote éventuellement d’une fonction de proximité à seuil. Cette fonction de proximité est en fait une façon de mesurer la distance entre deux exemples et donc de savoir si on les met dans la même catégorie ou pas, permettant ainsi de construire automatiquement des classes ou catégories d’exemples, suivant qu’ils sont proches ou éloignés. Ainsi le programme permet d’organiser les connaissances et éventuellement de les classer d’une façon nouvelle s’apparentant à des connaissances nouvelles. Si l’on veut classer les exemples, l’apprentissage non supervisé (dit aussi Apprentissage libre) nous dit aussi combien il faut de catégories ou boites dans lesquelles ranger nos exemples.
Apprentissage supervisé : on présente des exemples étiquetés et une fonction de proximité au programme, comme des images de feuilles d’arbres et le nom de l’arbre correspondant. L’apprentissage consiste alors en ce qu’au bout d’un certain nombre d’exemples, le programme soit capable d’associer un nom d’arbre à la feuille qu’on lui présente, non nécessairement issue de la base d’exemples précédemment étiquetés. L’apprentissage supervisé moderne peut-être plus complexe et le superviseur d’une nature plus sophistiquée, comme les réseaux de neurones formels[4].
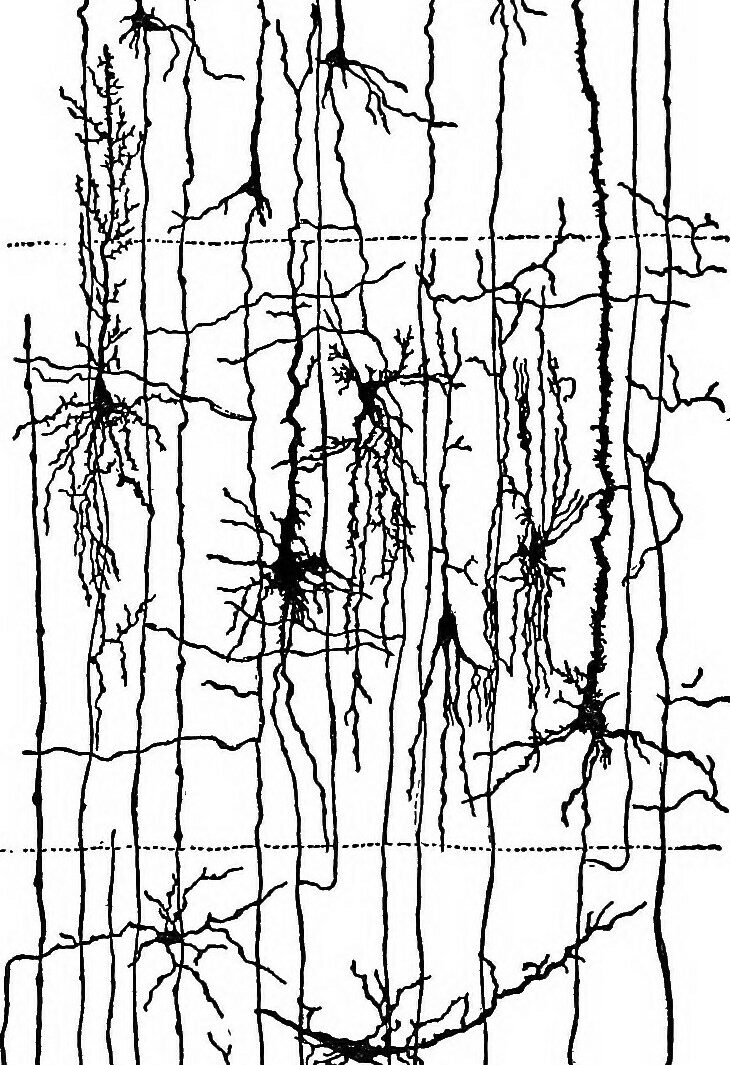
Neurone formel : il s’agit d’une généralisation du concept électronique de porte logique. Il s’agit d’un sommet d’un graphe à plusieurs arcs entrants et un seul arc sortant, le sommet (neurone) étant doté d’une fonction de seuil. La valeur de sortie (0 ou 1) est liée à la somme pondérée des valeurs entrantes ; étant issues de neurones formels, elles sont de valeurs (0 ou 1) et ont la fonction de seuil.
Chaque neurone formel peut être considéré comme un processus séquentiel communiquant classique, c’est le programme interne traitant les données qui fait la différence.
Réseau de neurones formels : c’est un graphe dont les sommets sont les neurones formels. Ce qui fait la pertinence d’un tel réseau, c’est la fonction d’activation associée aux neurones. On généralise en introduisant le concept de poids synaptique, c’est-à-dire des fonctions numériques sur les arcs d’entrée des neurones formels. La fonction associée au neurone formel est alors plus complexe. La programmation associée à ces réseaux est celle des réseaux distribués asynchrones en général[5].
Réseaux en couches : les réseaux de neurones formels actuels sont organisés en trois strates, le problème avec des centaines de milliers de connexions et donc de fonctions dites synaptiques est l’établissements de ces dernières. Il n’est pas raisonnable de penser le « faire à la main » on utilise donc ici l’apprentissage supervisé pour ce faire, ce qui permet à l’algorithme, à partir d’exemples, d’ajuster les coefficients associés aux synapses formelles pour étiqueter les exemples.
Les jeux d’échecs, alphaGo, alphaZéro, et autres Shogis
La puissance de calcul aidant, les bases de données massives permettent de passer à la vitesse supérieure. Alors que pour faire jouer un ordinateur aux échecs, on disposait depuis un demi-siècle d’algorithmes comme alpha/beta ou SSS⋆ économes en ressources[6] et propres au jeu lui même, auxquels il faut préciser les poids des différentes pièces et donner des fonctions d’évaluation, on peut avec d’énormes puissances de calcul se passer de ce type d’algorithme et faire découvrir les bonnes stratégies par des réseaux en couches associés à un apprentissage par renforcement lui-même basé sur le fait que l’on fait jouer l’algorithme contre lui- même avec une procédure arborescente[7] à choix probabilistes de type Monte Carlo[8]. Ces algorithmes d’I.A. n’assurent d’ailleurs pas d’obtenir une solution exacte, seulement une solution. Probablement, approximativement Correcte. Cet algorithme générique alphaZéro, après 4 heures d’auto-apprentissage a battu tous les autres programmes d’échec, 8h pour le GO, avec un parallélisme de niveau 64 générant 80.000 positions à la seconde sur une machine de puissance teraflopique (c’est-à-dire 1012 opérations par seconde). Ce qui fait au bas mot 1.843.200 positions de départ différentes examinées et au total 147.456.000.000 coups différents joués[9] ! Si avec ça l’ordinateur ne trouve pas une bonne solution, il y a du mouron à se faire.
Le mythe de la singularité
Comme on peut s’en douter à la lecture de cette description des réseaux de neurones formels, ils n’ont strictement rien à voir, malgré ce qu’en veut dire une vulgate très répandue, avec les neurones des cerveaux animaux, et a fortiori du cerveau humain.
Ce qui fait la puissance de nombre de ces algorithmes (pas tous, toutefois), c’est leur couplage avec les grandes bases de données et la puissance de calcul mise en œuvre.
L’enjeu est bien compris par les dirigeants des grandes nations : « Le pays qui sera leader en intelligence artificielle dominera le monde » (Vladimir Poutine, 2017)
L’intelligence humaine
L’intelligence humaine ne saurait être celle d’un individu. L’intelligence de chaque individu est celle de la société dans laquelle il vit. Ce que l’on nomme intelligence est une production sociale, et les outils fabriqués et conçus par les humains y participent, et en particulier l’informatique et ce qui est appelé I.A.
La puissance des algorithmes d’I.A. associée aux grandes bases de données, fait tourner la tête de quelques anglo-saxons pour lesquels l’intelligence est d’ordre syntaxique et ne font pas de différence notable entre intelligence humaine et « intelligence » artificielle. Le behaviorisme ou comportementalisme, consiste à s’attacher à ce qui paraît seulement, pas à ce que ça signifie, à la sémantique.
Cette façon de faire qui consiste à « singer » la nature n’a aucune valeur scientifique. La Nature n’a jamais inventé la roue, aucun avion ne vole comme un oiseau, ni aucun bateau ne navigue comme un poisson.
Du temps où les usines « tourneront » toutes seules
Ceci étant dit, la puissance phénoménale conférée aux humains par l’informatique, et plus généralement la Cybernétique laisse entrevoir, à condition que les hommes s’en emparent, une société où tous les biens nécessaires à la vie courante pourraient être produits quasi automatiquement avec une intervention humaine marginale et non comme maintenant une aliénation accrue. Comme Janus, ces sciences et technologies ont toujours deux visages. Laissant alors aux hommes le travail choisi, changeant ainsi même le sens du travail. Ce travail, devenant alors le premier besoin social de l’homme.
PAC ou Probablement Approximativement Correct[10], là est le secret de toute « intelligence ». Ainsi « l’intelligence » de la nature est-elle ce que l’on a appelé la théorie de l’évolution ce qui pour certains se traduit par struggle for life[11], ce qui est un monstrueux contre-sens utilisé par les idéologies fascisantes. En fait, l’évolution se fait à partir des moins inaptes, c’est la variété, la marginalité qui autorise les évolutions. L’espèce parfaitement adaptée à une situation donnée est appelée à disparaître dès lors que la situation change !
Comme déjà souligné, l’expression « artificial intelligence » devrait se traduire autrement en français, par le syntagme « Informatique Avancée » (ce qui garde les initiales I.A.) ou Extraction automatique des connaissances ou Apprentissage automatique. Ces algorithmes s’ils sont imbattables pour jouer (du moins dans les jeux de stratégie), n’ont pas créé de jeu, ils n’ont pas de sentiments, et plus généralement, on peut faire nôtre cette remarque de Pablo Picasso : « les ordinateurs sont ennuyeux, ils ne donnent que des réponses ».




{kind=link}